



We focus on two examples of growing networks with adoption mechanisms: citation networks and coauthorship networks. In both situations, the network grows over time and the mechanisms of growth depend on some system properties as well as individuals’ choice of adopting a new member in their networks. For instance, in citation networks, each new arrival paper selects existing papers to cite as references, and in coauthorship networks, each existing member adopts a new colleague, collaborator, or student in their collaboration circle.
We begin by studying the growth patterns of different groups in the citation network and the coauthorship network of the APS publication dataset (see the Data subsection in the Methods for details). The groups of interest in this study are the male-led papers and female-led papers in the citation network, as well as the male and female authors in the coauthorship network.
Group-level degree dynamics
In Fig. 1a we group the papers by the gender of the first author3 and plot the average in-degree growth curve for the nodes in each group. We can observe that the curves corresponding to the two different groups have a similar shape and a large portion of overlap. The average growths start as power functions (near straight lines in the log-log plot) but eventually saturate due to the gradual loss of interest. In particular, the average citation numbers 5 years after publication are 6.45 and 6.18 for the two groups (male-led papers and female-led papers) respectively. This indicates that the manner in which a paper’s number of citations grows is regardless of its first author’s gender, and the mechanism of preferential attachment with ageing applies similarly to the two groups.

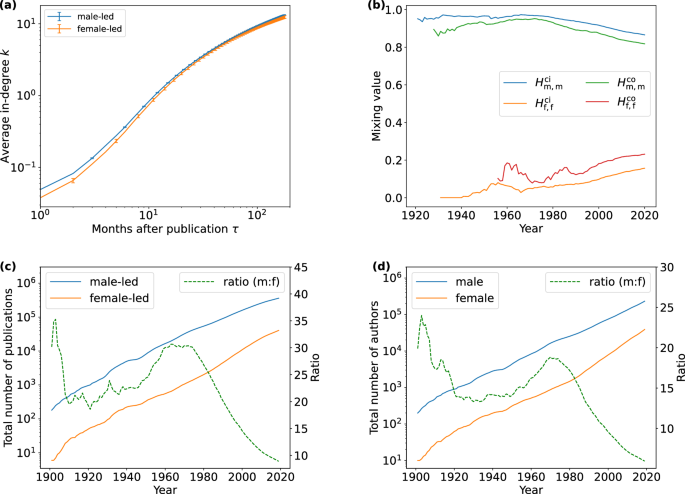
a The average in-degree (number of citations received) growth of papers with an age of no less than 15 years in the APS citation network. Papers are grouped by the gender of the first author. Self-citations are excluded. Error bars representing the 95% confidence intervals are computed via 500 bootstrap resampling iterations in the corresponding samples. b The evolution of the empirical mixing values of the APS citation network (Hci) and coauthorship network (Hco). The subscript m denotes males (male-led papers or male authors) and f denotes females (female-led papers or female authors). Note each data point in the plot corresponds to the mixing value for a moving time window of 10 years. Some values for early years are missing due to insufficient data. The evolution of the total number of publications or authors of different groups (blue and orange lines) and their ratio (green dashed lines) over time (c) is for the APS citation network, and (d) the APS coauthorship network. Note the left Y-axes (total number of publications or authors) use the logarithmic scale.
Adoption mechanism and mixing preferences
Next, we examine the group-level mixing preferences in the citation and coauthorship networks. This allows us to investigate how the homophilic effect influences the adoption and growth of the groups in the networks, and enables us to model the interplay between the group-mixing preferences and system-level growth dynamics.
Since we have two groups of interests in the network, we use a 2 × 2 matrix H to encode the directed mixing pattern of nodes in the two groups, where the first and second subscripts (m or f) denote the group assignments of the target and source nodes respectively. The mixing matrix H is normalised row-wise and can act as a right stochastic matrix (see the Model of network growth and adoption subsection for more details).
$$H=\left[\beginarrayccH_\rmm,\rmm&H_\rmm,\rmf\\ H_\rmf,\rmm&H_\rmf,\rmf\endarray\right].$$
(1)
Using the citation network as an example here, \(H_\rmm,\rmf^\rmci\) represents how likely an existing male-led paper in the network gets cited by a female-led new paper, and is defined as the fraction of citations from female-led papers to male-led papers among all citations to male-led papers. The empirical mixing matrix we observe in the entire APS citation network without self-citations is
$$H^\rmci=\left[\beginarraycc0.922&0.078\\ 0.901&0.099\endarray\right].$$
(2)
Similarly, we examine the mixing patterns in the coauthorship network, where \(H_\rmm,\rmm^\rmco\) and \(H_\rmf,\rmf^\rmco\) indicate how likely an existing senior author collaborates with a newly arrived junior author of the same gender in the data. The seniority of an author is based on the first appearance in the dataset. See Supplementary Methods: Data and network construction for more details about the network construction. The empirical mixing matrix we observe in the entire APS coauthorship network is
$$H^\rmco=\left[\beginarraycc0.837&0.163\\ 0.777&0.223\endarray\right].$$
(3)
Moreover, in Fig. 1b we plot the evolution of mixing values in the APS citation and coauthorship networks over time. In the citation network, for male-led papers, \(H_\rmm,\rmm^\rmci\) initially starts close to 1 until around the 1970s, then gradually decreases to around 0.85. For female-led papers, however, the situation is much different. \(H_\rmf,\rmf^\rmci\) starts close to 0 and gradually increases to 0.08 in the late 1950s, then decreases to below 0.03 in the late 1960s. Since then, it has gradually increased to the level above 0.15. The coauthorship network shows a similar mixing pattern to the citation network, where \(H_\rmm,\rmm^\rmco\) is also high but lower than \(H_{\rmm,\rmm}^{\rmci}\), and \(H_{\rmf,\rmf}^\rmco\) fluctuates at a low level and starts to increase steadily after the 1990s. For both networks, the gaps between Hm,m and Hf,f are getting smaller in the last few decades.
Co-evolution of group size ratios and mixing values
Figure 1 c shows the total number of publications for male-led and female-led papers over time. The sizes of the two groups have a large gap, which is getting smaller in the last few decades after the 1980s. We also plot the ratio between the two group sizes as the dashed green curve. The ratio starts at a high level from around 30 to 35, due to the small size of the network and very few female-led publications, but quickly decreases to a low range around 20 as the system grows. Subsequently, it increases with some fluctuation and reaches a plateau back to 30 during the 1960s to the 1970s. After the 1980s it steadily decreases, to the level of around 8.70 in the year 2020.
Figure 1d shows the growth patterns of the numbers of male and female authors and their ratio. The trend is similar to Fig. 1c at the start. However, its peak has a visible delay after the 1970s compared with the ratio of the publication numbers. The ratio of the author numbers decreases to around 5.54 in the year 2020 which is much lower than 8.70, reflecting lower productivity of female researchers than male researchers20. The high ratio of male-to-female authors at the start can also be related to the first-mover advantage of male researchers in physics, which might be due to historical barriers of entry for female researchers3. The male-to-female ratio peaks in the 1970s and decreases rapidly afterwards, suggesting more involvement of women in STEM fields in recent years.
When we compare the evolution of the mixing values and the evolution of the group ratios, we find that when \(H_{\rmf,{{\rmf}}}^{{{\rmco}}}\) declines in the 1960s, the paper number ratio climbs to a high plateau too. On the contrary, the corresponding peak of the author number ratio in the 1970s has a noticeable delay. The decline of \(H_{\rmm,\rmm}^{{{{\rmco}}}}\) and \(H_{{{{\rmm}}},{{{\rmm}}}}^{{{{\rmci}}}}\), as well as the increase of \(H_{{{{\rmf}}},{{{\rmf}}}}^{{{{\rmco}}}}\) and \(H_{{{{\rmf}}},{{{\rmf}}}}^{{{{\rmci}}}}\) after the 1980s, correspond to the approaching gaps between the group sizes.
The disparity we observe in the mixing pattern in \(H_{{{{\rmm}}},{{{\rmm}}}}^{{{{\rmco}}}}\) and \(H_{{{{\rmm}}},{{{\rmm}}}}^{{{{\rmci}}}}\) cannot be simply explained by the different group sizes, as these do not account for the differences in each row. Nor, can it be simply explained by the systematic differences in the quality of the two groups, as we have shown in Fig. 1a that the average citation growth curves are similar for the papers in the two groups. To accurately model this phenomenon, it is essential to consider the network growth and adoption process, which will be discussed in the next section.
Model of network growth and adoption
The empirical investigations mentioned above suggest that growing networks that operate through the adoption of new nodes and links have system-level properties with asymmetric group-level mixing. To address such cases, we propose a network model of growth and adoption that consists of two mechanisms: general preferential attachment and asymmetric mixing. For the former, we adopt the preferential attachment network model introduced by Sun et al.18. For the latter, we generalise the mixing model introduced by Karimi et al.21.
An important difference between our proposed network adoption model and the previous models is that, instead of solely depending on the properties of the existing node (e.g., its degree, fitness or age), the attachment of a new node to an existing node is done based on the properties of both the new node and the existing node.
In the preferential attachment network model, the selection probability Π of an existing node determines how likely it attracts new links. Translating this into our scenarios, Π can be interpreted as the attractiveness of a scientific paper in a citation network or a senior scientist in a coauthorship network. In the general preferential attachment model we use in this study, Π has the form
$$\Pi \sim k\eta R(\tau ),$$
(4)
where k is the node’s degree, η is the node’s fitness, and R(τ) is the ageing function where τ is the node age. The node degree k is a classical amplifier in preferential attachment network models22 that can be introduced by various mechanisms such as the reference-copying process23. The positive feedback loop here, with Π being monotonic to k, reflects the rich-get-richer effect or the Matthew effect24. The node fitness η reflects the intrinsic differences between nodes15. Fitness stays constant for a node during its lifetime and is typically drawn from a distribution ρ(η) that does not change over time. Fitness can be interpreted as the quality of a scientific paper, or the research excellence of a senior researcher in our scenarios. The aging function R(τ) is typically a decreasing function that starts at R(0) = 1, which represents the gradual loss of the node’s “relevance” 9. It reflects the natural preference for novelty and contributes to the eventual slowdown of the degree growth, limiting the first-mover advantage of old nodes.
Next, we turn our focus on the gender disparity in received citations observed in Fig. 1b. This disparity, however, cannot simply be explained by the systematic differences in the quality of the two groups (male- and female-led), as we have shown in Fig. 1a that publications led by males and females have comparative quality as indicated by their similar average citation growth curves; nor can it be explained by the differences in group sizes. In our study, we regard this disparity as an intrinsic property of the system, namely, asymmetric mixing, and it acts as a fundamental mechanism in our model.
In order to address this, we model the network with two types of nodes that are labelled 1 or 2. The label of a node represents the node’s attribute and does not change over time. We refer to the nodes of the same attribute as a group. In general, there can be more than two groups in the network as shown in Supplementary Results II: Simulation with three groups.
Next, we define the mixing matrix H that denotes how likely the nodes connect to each other based on their attributes, with Hi,j denoting the likelihood of an existing node from group i to attract a new link from a new node from group j. In our case, since there are two groups in the network, the mixing matrix H is 2 × 2.
Each element in the mixing matrix Hi,j ranges between 0 and 1, such that Hi,i = 1 means an existing node from group i always gets connected to by a new node from the same group, and Hi,i = 0 means that an existing node from group i always gets connected to by a new node from a different group. It is convenient to define H as a right stochastic matrix with each row summing to 1, i.e., for any given i,
$$\sum_jH_i,j=1.$$
(5)
The value Hi,j can thus be interpreted as the conditional probability that an edge starts from a node in group j, given that it points to a node in group i. Note we should be careful about the edge direction here. Even with Hi,i = 1, a new node from group i can still connect to an existing node from a different group j, since Hj,i is not necessarily 0. The exact mixing values of a real network can be inferred by counting the fractions of different types of edges in the network (see the Inferring mixing matrix from data subsection in the Methods for details).
To combine preferential attachment with asymmetric mixing in our framework, we distinguish two fundamental mechanisms in the network: growth and group assignment/adoption, each governed by preferential attachment and asymmetric mixing respectively and independently. This separation here is supported by the empirical observation of group-independent degree growth.
The growth mechanism includes the arrival of new nodes, the degree growth of existing nodes and the network growth: New nodes join the network and connect to existing nodes, thereby increasing the degrees of those existing nodes and contributing to the overall network expansion. This process is primarily governed by preferential attachment, as demonstrated in Eq. (4).
For the adoption mechanism, we turn to the properties of group mixing preferences. In real networks, the attribute of an individual node might be known or unknown when it joins the network depending on the context. In coauthorship networks, for instance, senior collaborators often recognise the gender of the junior new collaborators. In citation networks, although this information might be hidden when making citations, it can still shape citation behaviour through various formal or informal channels, such as social interactions at conferences and other gatherings that raise awareness of different publications. The attribute of a new node can also be affected by many factors in real life. More specifically, in the setting of coauthorship networks, factors such as the total capacity (free hands) of researchers in group i to adopt the junior researcher in group j in their personal network, and the willingness of the junior researcher to collaborate with senior researchers in group i, can all affect whether a collaboration (i ← j) takes place.
To enable our model to target more general cases, we assume that the attribute of a new node is a random variable determined only when it joins the network. We use pj to denote the probability that a new node belongs to a given group j. Given the attributes of the nodes to which the new node attaches, the probability distribution p of the attribute of the new node can be inferred from the mixing matrix H: If the new node connects to mi existing nodes from group i, we get
$$p_j=\frac\sum_iH_i,jm_i\sum_im_i,$$
(6)
where the numerator is the weighted sum of all mi, with each weighted by the corresponding entry in the mixing matrix Hi,j, and the denominator ∑imi is the total number of links the new node creates, ensuring normalisation such that ∑jpj = 1. Figure 2 shows a simple illustration of growth and group assignment.

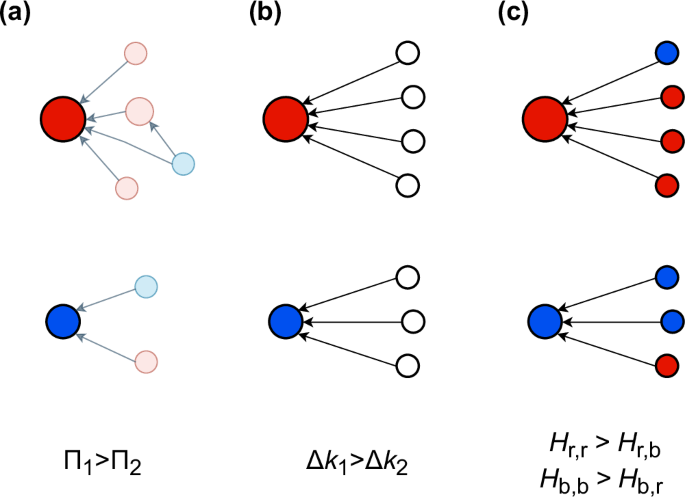
a Two existing nodes with their ego networks (greyed out) that belong to different groups, indicated by different colours (r: red and b: blue). The size of a node indicates its Π, i.e., how attractive the node is. b New nodes arrive and attach to the existing nodes based on their attractiveness Π. For simplicity, each new node only attaches to one existing node. c Inferring the labels of the new nodes using the mixing values in H. The mixing matrix H used in the figure is only for illustrative purposes and does not represent real data.
Deriving group size ratio from mixing matrix
In the empirical observations, we demonstrated that the group size ratios and the mixing values of the network co-evolve over time. This phenomenon can be analytically explained using our model with preferential attachment and asymmetric mixing, in which the mixing matrix H alone is sufficient to determine the stationary ratio of the group sizes in the network.
We use vector n to denote the group sizes, where ni(t) denotes the size of the group i at timestep t. When there are sufficiently many nodes in the network, the change of the group sizes in the next time step t + 1 can be written as
$$n_j(t+1)-n_j(t)=\lambda \sum_iH_i,jn_i(t).$$
(7)
Equation (7) describes how the group sizes n evolve over time given the mixing matrix H. Similar to Eq. (6), the size change of a certain group j is proportional to the weighted sum of all group sizes ni, with each ni weighted by the corresponding entry in the mixing matrix Hi,j. The constant λ > 0 determines how fast the network size grows. Using an equivalent matrix expression, we obtain
$$\boldsymboln(t+1)=\boldsymboln(t)\cdot (\lambda H+I).$$
(8)
where I is the identity matrix. Let vector ϕ denotes the group fractions, i.e.,
$$\boldsymbol\phi =\frac1N{{\boldsymboln}},$$
(9)
where n is normalised by the network size N = ∑ini. This leads to a power iteration process, whereby ϕ converges to the first left eigenvector of the right stochastic matrix H (note H and λH + I share the same eigenvectors). Therefore, if the mixing matrix H remains constant over time, the group ratio will eventually converge, owing to the growing network size. The size of any group will eventually occupy a fixed fraction of the network size. When the mixing matrix H undergoes changes, the group size ratio ϕ will approach the eigenvector of the updated H. In the next section, we will validate this analytical result experimentally.
Experimental validation
To validate our model and the analytical results, we conduct experiments based on simulation with synthetic networks. The main focuses of the simulation are: (i) to validate if the growth of group sizes and the evolution of their ratio follow our analytical prediction, and (ii) to investigate how the intervention of mixing values changes the group balance.
Figure 3a, b demonstrate the simulation results of the synthetic network with the initial configuration of the APS citation network as of the year 1955 and the evolving empirical mixing values from 1955 to 2020. We select this period to avoid the fluctuations during World War II and the post-war period. More details of the simulation settings can be found in the Simulation settings subsection in the Methods.

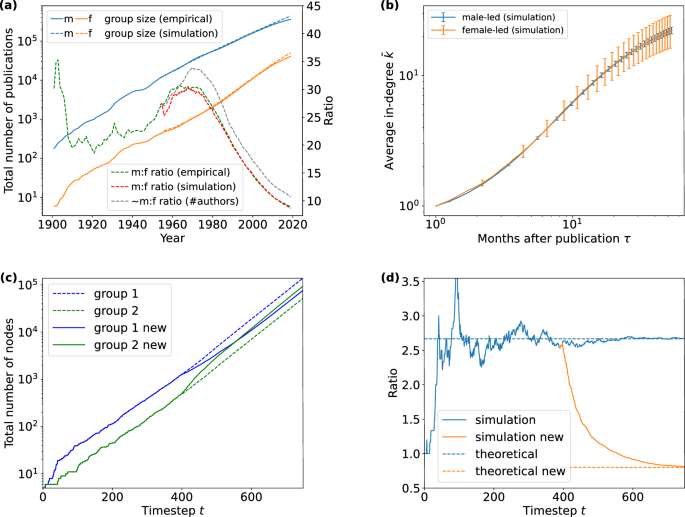
a The group size growths of male-led papers (dashed blue) and female-led papers (dashed orange) and their ratio (dashed red) in the synthetic network from 1955 to 2020 with empirical mixing values. The synthetic results are compared with empirical values: group size growths (solid blue and orange) and ratio (dashed green). Furthermore, we indicate the empirical trend of the ratio between male and female author numbers (dashed grey). The left Y-axis (total number of nodes) is in logarithmic scale. b The average degree growth of nodes in the two groups (blue and orange) in the synthetic network with empirical mixing values. Error bars representing the 95% confidence intervals are computed via 500 bootstrap resampling iterations in the corresponding samples. c The growths of sizes of the two groups (blue and orange) in the synthetic network where we alter the mixing matrix at t = 400. The dashed lines after t = 400 indicate the group sizes with the unaltered mixing matrix. The plot uses the log-linear scale. d The ratio of the two group sizes in the synthetic network where we alter the mixing matrix. The orange curve after t = 400 shows the group size ratio with the altered mixing matrix, while the blue curve corresponds to the unaltered mixing matrix. The dashed lines indicate the corresponding theoretical asymptotes calculated with Eq. (8).
In Fig. 3a the group sizes of male-led papers (dashed blue) and female-led papers (dashed orange) in the synthetic network grow with similar trends as the empirical data indicated by the corresponding solid curves. We also track the evolution of the group size ratio (shown as dashed red) and observe that, despite some fluctuations at the outset, it closely follows the empirical trend depicted as dashed green.
For comparison, we also plot the empirical trend of the ratio of author numbers, which we do not use as input in the simulation. The dashed grey curve is proportional to the ratio between male and female author numbers, with the value of 1955 aligned to the dashed green and dashed red curves for better visual comparison. The ratio of author numbers exhibits significant deviation from the ratio of publication numbers, with a noticeable delay. This suggests that the mixing matrix plays a more influential role than just the ratio of author numbers in determining the evolution of the ratio of publication numbers.
In Fig. 3b the average degree growth curves of the two groups exhibit realistic growth patterns with saturation and largely overlap, similar to those observed in Fig. 1a. The error bar of the female-led papers is larger due to the smaller group size.
The experimental results can well recover the observations in Fig. 1. This shows that our network growth model of preferential attachment and asymmetric mixing is able to reproduce the co-evolution of group size ratios and mixing values in the empirical data.
Interventions to overcome group-ratio disparity
The empirical exploration and the proposed network model suggest that in the absence of any intervention, the system could persistently give cumulative advantages to one group due to asymmetric mixing preferences, assuming other system-level properties are group-independent. In this scenario, one might naturally ask whether network-level interventions could be effective in reaching group-size parity, and under what conditions the networks would yield more balanced groups.
Our model allows us to investigate different interventions to the system and their effects, thereby enabling us to answer such counterfactual questions. In fact, the derivation in Eqs. ((7), (8), (9)) already shows that by setting the appropriate mixing matrix H, one can steer the group ratio to converge towards a desired value.
In the experiment that follows, we intervene in the system by altering the mixing values during the simulation. The initial mixing matrix results in a dominant group 1, while the altered mixing matrix is slightly in favour of group 2 according to our model (see the Deriving group size ratio from mixing matrix subsection in the Methods for details). The results in Fig. 3c, d show that the intervention on the mixing values can effectively change the group balance. After the intervention, the size of group 2 surpasses group 1, and the ratio of the two group sizes quickly converges to the theoretical value according to the new mixing matrix.
In the simulation, we also observe the fluctuations of the group ratio and group fractions at the start due to randomness and late arrival, similar to the ones we observe in the empirical data (Fig. 1c, d). Nevertheless, the group ratio and fractions ultimately converge to the theoretical values predicted by our model as indicated by the dashed lines. This shows that our model is robust to the randomness in the initial condition.
In the societal context, such intervention translates to convincing individuals to change their preferences towards diversifying their network. In the citation context, this could mean imposing certain constraints on citation preferences25. In the scientific collaboration context, this could mean training senior scientists to adopt junior scholars with diverse backgrounds, or providing financial support for those scientists in need. While these scenarios are theoretically possible, discussions related to their validity, feasibility, and societal impact require further investigations in future works.
link