



Local search algorithm
Cluster analysis and community detection share many conceptual similarities, but often have a contrasting focus. Cluster analysis puts emphasis on the center of a cluster15,16, while community boundaries often play a more predominant role in community detection37. Community centers can be inferred from some community detection algorithm outputs, for example, the nodes associated to the largest absolute weights of the leading eigenvector of the modularity matrix, or exhibiting a higher density of connections inside the communities, are deemed to be community centers, core members or provincial hubs23,38. But centers are only a by-product of those algorithms, rather than at their core of methodologies. The approach that we propose here is explicitly focusing on community centers to identify clusters, which is motivated by the existence of underlying asymmetries between nodes19,20,21, the concept of local leaders18 in networks and borrows ideas from density and distance based clustering algorithms on vector data16. In our local search (LS) algorithm, the local dominance refers to a leader-follower relation, and we pose a further restriction that each node has eventually at most one out-going link pointing to its leader. We hypothesise that communities are organized around centers that are nodes with both a dominant position in its neighborhood (e.g., has a larger degree, or other centrality measures, than its neighbors) and distant enough from other potential centers. Then based on community centers, partition is naturally ensuing. The process of our LS algorithm involves four steps:
Firstly, we calculate the degree ku of each node (see digits in Fig. 1a). Secondly, we point each node u to its largest-degree-neighbor v if this neighbor is no smaller than itself on degree (i.e., kv ≥ ku and \(k_v=\max \ j\in V(u)\\), where V(u) is the set of neighboring nodes of u). Nodes with in-going edge(s) and no out-going edge are local leaders18 that dominates its vicinity (see nodes f, m, and p in Fig. 1b). Such local leaders are like rich-among-poor and are potential community centers. Thirdly, for each local leader u, we use a local breath-first searching (LBFS) to find it a nearest local leader v with kv ≥ ku and record its shortest path length to node v as lu = duv, which is larger than one (see long-dash arrows in Fig. 1c, and see Fig. 1d for a better extracted local dominance relation, which is in a reverse direction of arrows). The LBFS process stops after finding such a local leader v, which is the reason why we call it local BFS, so it generally searches a small region and does not traverse the whole network. For local leader(s) with the maximal degree, we do not perform such a LBFS, and directly assign the maximal lu of other local leaders (see mathematical descriptions in Methods).


a An example network where digits on nodes and size of nodes indicate the degree. b The identification of local leaders based on local dominance by creating a forest of directed acyclic graphs (DAGs) as indicated by short dashed directed edges. For each node u, it points to any adjacent neighbor v with kv ≥ ku and \(k_v=\max \{k_z| z\in \bfV(u)\}\), where V(u) is the set of neighboring nodes. In this example, nodes are traversed by their lexicographical order, when node b is traversed, it points to m as \(k_m=\max \{k_z| z\in {{{{{\bfV}}}}}(b)\}\ge k_b\); later, when m is traversed, it has no out-going link, and so m is identified as a local leader: it does not point to any of its followers and its remaining neighbors all have smaller degrees. When there are more than one neighbor with the same largest degree, more than one directed edge is temporarily added, e.g., node c points to both b and m as \(k_b=k_m=\max \{k_z| z\in {{{{{{{\bfV}}}}}}}(c)\}\ge k_c\); nodes d and l also have more than one outgoing link. The local leaders, which are potential community centers, are f, m, and p (indicated by dark gray color). c Each node randomly retains just one out-going edge shown as a short dashed directed edge (e.g., c can point to b or m with an equal probability, similarly for l and d). Then, for each local leader u, a local-BFS is performed to find its nearest local leader with kv≥ku, and the shortest path length on network duv, ∀ v is designated by lu. Here, p → f with lp = 2, and f → m with lf = 4. In (c), short-dash arrows and long-dash arrows correspond to pure followers (whose lu = 1) and local leaders (whose lu≥2), respectively. Each node has at most one out-going link (u → v), which can go beyond direct connections. The local leader(s) with the maximal degree has no out-going link (here node m). d The corresponding tree structure formed by local dominance. The scale on the left is a visual aid for calculating li between connected nodes in the DAG. e The scatter plot of ki and li for all nodes. Community centers are of both a larger degree ki and a longer li. f The decision graph for quantitatively determining community centers (indicated by triangles) based on the product of rescaled degree \(\tildek_i\) and rescaled distance \(\tildel_i\) (see more details in Supplementary Note 1.2). Community centers can be detected by a visual inspection for obvious gaps or sophisticated automatic detection methods. Here, two centers, nodes m and f, are identified. The color of nodes in (c) and (d) represents the community partition, and community centers are highlighted by a darker hue of the same color.
After performing LBFS to all local leaders except the maximal one(s), we can determine community centers according to degree ku and distance along the local dominance relation lu (in the network in Fig. 1, nodes f and m stands out as centers, which have both a large ku and lu, see Fig. 1e). Note that for nodes except local leaders, their lu = 1. By multiplying normalized ku and normalized lu, we can better quantitatively identify community centers via a notable gap between candidates (see Fig. 1f, and details in Methods and Supplementary Note 1). Lastly, after the identification of community centers, the group label can be assigned to its followers along the local dominance relation (i.e., the reverse direction of arrows in Fig. 1c) in one single step.
We name our framework as local search (LS) algorithm, since it only require local information of nodes and rely on efficient LBFS processes for local leaders, which takes up a very small fraction of the whole network (see Supplementary Table 1). The identification of local dominance relation is quite resilient to missing and noisy links. Our LS algorithm is of a linear time complexity in terms of the number of edges (see Methods and Supplementary Table 1) and is in no need of iteratively optimizing an objective function that relies on a global null model in other state-of-the-art methods9,26,27,28,29 or resorting to spreading dynamics30,31. In addition, our LS algorithm is also capable of identifying multiscale communities structure, as local dominance relation also provides us hierarchies between communities via asymmetric relationship between communities centers. The strength of our framework is demonstrated on several classical challenging synthesized test cases and empirical network datasets with ground-truth community labels. Finally, we also show how it provides a connection to clusters in a metric space, and our LS algorithm outperforms current state-of-the-art unsupervised both clustering and community detection methods when applied to discretised vector data clouds.
As the implementation of our algorithm was done in Python, we use the NetworkX package implementation of the Louvain algorithm, our main point of comparison, as they are both of a linear time complexity, to obtain fair comparison for running time. We also compare with a broader range of popular community detection algorithms on partition performance, some of which are slower but more accurate ones. Our LS algorithm still ranks first or second on the partition performance for five out of seven networks. More details of our LS algorithm can be found in Methods and Supplementary Note 1.
Synthetic networks
Here, we use well-known benchmark networks to illustrate how the LS method functions and in which situations it performs well. For illustration, we mainly contrast the results obtained by the LS method to those obtained by the Louvain method9, which is widely applied due to its good performance and high efficiency. In addition, both algorithms have a linear time complexity, and thus the comparison on performance between them are more meaningful. We first look at a circular regular network, where all nodes are equivalent and thus no community structure should be discovered. LS correctly identifies a single community (Fig. 2a), by contrast, modularity forces community structure to exist and finds five communities (Fig. 2d). Let us look in detail at the reason why LS finds a single community. First, each node will point to all its adjacent neighbors as they all have the same degree, and since node are sequentially traversed and they will not point to their followers, loops cannot be formed, see Supplementary Fig. 1c and Supplementary Note 1.1.1 for a proof. After all nodes have been considered, each node will only keep one outgoing link with an equal probability, and eventually a tree structure will be formed. Because of the homogeneity of the graph, the tree only allows the identification a single community center and therefore of a single community. Because all nodes are equivalent, the labeling and thus order in which they are visited, is irrelevant. We note that in the case of a clique, an extreme case of regular network, the mapping of local hierarchy can yield a range of structure from a chain to a star structure, see Supplementary Fig. 1b for more details. In all cases, only one center is identified. By contrast, the Louvain method would partition a homogeneous regular network into several communities by optimizing modularity (see Fig. 2d).


The heterogeneity increases from left to right. The color of nodes denotes the community membership. a In a strict homogeneous regular network (N = 36, 〈k〉 = 4), all nodes are identical, only one community is detected by the LS algorithm (see Supplementary Fig. 1 for more details); In an Erdős-Rényi (ER) random network (N = 64, 〈k〉 = 4), there may exist some communities due to randomness36, b the LS algorithm detects only a few communities. In a Ravasz-Barabási network43 that displays stronger heterogeneity, c the LS algorithm groups all first-level nodes and all sixteen second-level peripheral clusters into one community, and four small communities emerge (see Supplementary Fig. 4 for more details). d By contrast, the Louvain algorithm detects five communities by optimizing modularity in the same strictly regular network as in (a). e And the Louvain algorithm detects a lot more communities in the same ER network as in (b). f In the same Ravasz-Barabási network as in (c), the Louvain algorithm partitions each second-level branching as a separate community and misclassifies a first-level peripheral cluster into its own community, a result of traversal order and modularity optimization process in the Louvain algorithm.
Our second application focuses on Erdős-Rényi (ER) random graphs, which is still relatively homogeneous though not strictly homogeneous. While in the limit of an infinite random graph no community structure exists, in finite-size ER graphs, fluctuations may create spurious community structures11,36, as well as weak or spurious hierarchies between nodes. In this example, the LS method detects fewer communities than the Louvain algorithm, see Fig. 2b, e. In ER random networks, the degree distribution is relatively restricted around its average, but the system nonetheless exhibits fluctuations in the degrees. Large degree nodes are more likely to connect to each other, as the connection probability between them, kikj/2E, are among the highest ones. When two large nodes are connected, there will be a directed out-going link pointing from one node to the other, making one of them a follower. Thus the LS method detects fewer communities. On the other hand, when we fix the size of the network and increase the connection probability p, the number of communities detected by the Louvain algorithm also decreases but it consistently finds more communities than the LS method (see Supplementary Fig. 2). In addition, we are able to detect isolated nodes as noise (see gray nodes in Fig. 2b), as these nodes are of a small degree but infinite li.
We also consider an extension of the ER random graph model, the stochastic block models (SBM) shown in Supplementary Fig. 3 and discussed in Supplementary Note 1.1.2. For random networks generated by SBM39,40,41 with two blocks, when the inter-connection probability is zero, cout = 0, the Louvain algorithm detects two communities that align with ground truth, but this is a reflection of the resolution limit42, as when analyzing each community (each ER graph), it may partition it into more than ten communities (see Supplementary Fig. 2). By contrast, the LS algorithm still detects as many community centers as when looking at each individual random network. This result can be understood by the local nature of the algorithm, where the structure of one disconnected cluster does not affect the communities found in the other and thus LS algorithm does not suffer from resolution limit. And when fixing the intra-connection probability cin and increasing cout, the boundary of the two communities becomes blurred. We find that when slightly increasing cout, the number of community partitions given by the Louvain algorithm increases drastically (see Supplementary Fig. 3b). By contrast, the F1-score of the LS algorithm is relatively stable, though not too high, and outperforms Louvain when cout is larger (see Supplementary Fig. 3).
Finally, we consider a hierarchical benchmark, the Ravasz-Barabási network model43 with two layers, which naturally provides a model with a hierarchy between the center and peripheral nodes. The clustering proposed by LS method groups explicitly reflects the hierarchical nature of the model by grouping first-level nodes and all sixteen second-level peripheral clusters into one community that centers at the original seed node, as it dominates their neighborhood; and four small communities emerge due to the existence of four local leaders (see Fig. 2c), which have a degree larger than their neighbors and a longer path length to the original seed node, i.e., li > 1, see Supplementary Fig. 4c for the decision graph that identifies community centers. The Louvain algorithm offers an alternative partitioning that ignores the hierarchical nature of the model and finds five communities of roughly equal size, and misclassifies a peripheral cluster as a separate small community (see Fig. 2f). This example is interesting in that the clustering provided by Louvain here provides a reasonable, yet alternative, answer that ignores one aspect of the data. This reminds us that different clustering methods rely on different underlying mechanisms and, as often occurs when using unsupervised methods, the outputs are rarely strictly right or wrong. The outputs should be understood not only in terms of the data, but of the methods as well. Still, it is worth noting that the Louvain algorithm misclassifies a first-level peripheral cluster into another community (see the blue cluster in Fig. 2f), due to the traversal order used by the algorithm and modularity optimization process (see Supplementary Note 1.1.3 for more details). When we further modify the network generated by the Ravasz-Barabási model by adding a third-level branching to one of the second-level central cluster, and add noise in the connectivity to other second-level central clusters, the LS method still detects meaningful hierarchical structure, see Supplementary Fig. 4b and Supplementary Fig. 4d.
Detection of multiscale community structure
As partially reflected in the decision graph of the LS algorithm for the Ravasz-Barabási network (see Supplementary Fig. 4c, d), the reliance on local dominance of our method to identify local leaders naturally lends itself to detect multiscale community structure14,34,44. To illustrate this point, we generate a multiscale network made of two levels: four top-level communities with 400 nodes each and inter-connection probability p1 = 0.0002, each top level community contains four second-level communities with 100 nodes each and p2 = 0.03514,34. Each second-level community is generated by the standard Barabási-Albert model45 with m = 7 that yields 〈k〉 = 14 (see Fig. 3a). The LS method correctly identifies two levels of community structure with a notable gap between first four top-level centers, which have similar \(\tildek_i\times \tildel_i\), and other potential centers, as shown in Fig. 3b. Then taking the twelve subsequent centers, these sixteen centers together correspond to the sixteen second-level communities, and their affiliation within each top-level communities are correct (see the tree structure for local leaders in Fig. 3c). As all sixteen second-level communities are statistically equivalent, the directionality of community centers (Fig. 3c) is determined by fluctuations in the network generating mechanism. The partition obtained by the LS method has an F1-score of 0.99 at the top level and of F1 = 0.56 at the second level. Misclassifications at the second level mainly come from a relatively large inter-connection probability p2, which blurs the boundary between communities. In comparison, the Louvain algorithm only detects four large communities that correspond to the top-level ones with F1-score equals 1, but it cannot detect second-level smaller communities due to the resolution limit42. This demonstrates the strength of the LS method on detecting smaller scale community structure.


a This network comprise four top-level communities (labeled as a, b, c, and d) with 400 nodes each and an inter-connection probability p1 = 0.0002, each of which further comprises four second-level communities with 100 nodes and p2 = 0.035 (e.g., community c comprises c1, c2, c3, and c4). The second-level communities are generated by the Barabási-Albert model45 with m = 7, which leads to an average degree 〈k〉 = 14. b shows the decision graph for the LS method when analyzing the network in (a). c displays the hierarchical structure formed by the local dominance between identified centers of each community. For better clarity, community centers are named by the community label instead of the real index of the node, and we only show the tree structure of these centers. The height difference indicates the li of the lower node. (d)-(f) is the same as (a)-(c), with only changing the generation process of second-level communities to the Erdős-Rényi random network with a connection probability p = 0.14, which still leads to the same average degree 〈k〉 = 14. In such a setting, similar to stochastic block models, nodes in the network are again relatively homogeneous. For better clarity, in (e) and (f) only top sixteen centers are labeled and their affiliation relation are visualized, and in total, LS detects 29 centers at the second-level for this network. For the multiscale network in (a), the LS method detects four top-level communities with F1 = 0.99 and 16 second-level communities with F1 = 0.56. For the network in d, the LS method detects four top-level communities with F1 = 0.89 and 29 second-level communities with F1 = 0.29. In both cases, the Louvain algorithm only obtain four communities, which corresponds to the first-level ones, with F1 equals 1, however, it cannot detect second-level partitions. By comparing results in (a)-(c) and in (d)-(f), we can find that our LS algorithm works well on networks with stronger heterogeneity. Results shown here correspond to just one realization, in multiple realizations, as every first- and second-level communities are equivalent, the label sequence in (b) and (e) and the tree structure in (c) and (f) may vary but have a consistent structure.
One reason that LS works on detecting multiscale structure resides in the fact that the average path length between nodes is governed by the connection probability46. The distance between nodes from different second-level communities within the same top-level community is on average shorter than the distance between nodes from different top-level communities, and thus the hierarchical structure is uncovered by the LS method. Another reason is the intrinsic heterogeneity in each second-level community.
By contrast, when keeping the average degree and inter-connection probability (p1 and p2) the same, and replacing the second-level communities by ER random networks with p = 0.14, which also yields 〈k〉 = 14 (see Fig. 3d), the whole network becomes more homogeneous (see Supplementary Fig. 5). In this case, the LS method can still detect four top-level communities (see Fig. 3e) but mis-identify some second-level communities (e.g., communities c2 and d1 are missing in this example, see Fig. 3f) and detect more smaller communities (29 second-level communities are detected instead of 16). The mis-identification of some second-level communities is due to the largest degree node u in those ground-truth communities being directly connected to a node v in other communities with kv ≥ ku, and thus u is considered as followers. This is more common in such a random setting, as there are more nodes with a relatively large degree beyond the reference value (i.e., the smallest degree of all of the largest node in each ground-truth second-level communities, see Supplementary Fig. 5 for more details). By contrast, in the scale-free case, there are fewer nodes beyond the reference value. For example, in the random multiscale network in Fig. 3d, the reference value is 34, and there are 60 nodes beyond it; in comparison, in the scale-free one, there are only 31 nodes beyond its reference value. The homogeneity makes the detection of such communities harder, if this minimum value become only slightly smaller, there will be much more nodes beyond the reference value in the random setting (see Supplementary Fig. 5b). Mis-affiliation, i.e., one local leader in community b3 follows the center of d4 instead of other centers in community d, is also partially due to a similar reason and partially due to randomness. The discussion above also imply that the LS method would be vulnerable to targeted failure – connecting two community centers would diminish one center as a follower and their corresponding communities merge as one (see Supplementary Fig. 24). In addition, due to randomness, two or more local leaders might emerge in the same second-level communities, which will lead to split of the community (e.g., there are two local leaders in communities c2). These would constitute cases where the LS method is not appropriate.
Real-world benchmark networks
We now test the LS algorithm and demonstrate its strength on several empirical benchmark networks (see Table 1) with known ground-truth community labels, see Table 2. We chose to compare with the Louvain algorithm in Table 2 because both algorithms are linear, making them well-suited for large-scale networks and facilitating a more meaningful comparison, and the Louvain method is the most widely used community detection algorithm implemented in most network packages. LS is faster than Louvain for 7 of the 8 benchmarks. The speed advantage becomes more noticeable as the networks get larger (see Table 2). For example, for the DBLP (Digital Bibliography & Library Project) network47 with 317,080 nodes and 1,049,866 edges, our LS method takes 45 s, while Louvain takes 256 s.
The LS method is not only faster, but also classifies better than the Louvain algorithm measured by the F1-score for 5 out of 7 examples with ground-truth community labels (see Supplementary Fig. 9 and Supplementary Note 2 for more details and discussions on the evaluation by F1-score, and we also make comparisons between algorithms on performance evaluated by conductance47, see Supplementary Table 4). In Table 3, we extend our comparison of the LS algorithm to include other popular algorithms with different perspectives on community detection, some of which are with greater accuracy albeit slower in implementation. For example, the geodesic density gradient (GDG) algorithm48 first embeds the network into vector space based on shortest path length between nodes and then applies an iterative clustering algorithm, which is similar to mean-shift algorithm49, both of which are costly in computation, to obtain partitions of communities. GDG algorithm achieves the best performance in two out of seven networks, and has an obvious advantage over other methods on Citeseer (see Table 3 and Supplementary Table 2 for more details). Another important type of method is inferential ones, which provides powerful tools without arbitrariness and further advances our understanding of community structure of networks50. Inferential algorithms, which generally rely on SBM as generative models, can explain the inability to detect communities in the very sparse limit51, help eliminate the resolution limit in Louvain algorithm and detect hierarchical structure of complex networks52. Inferential methods can be adapted to different types of networks ranging from weighted networks53 to directed ones54 and hypergraphs55. However, inferential methods are generally computationally expensive52,56. The inferential algorithm described in Refs. 52,56 has a much better performance than the LS on the Football network (see Supplementary Table 3), whose degree distribution is quite homogeneous. Other algorithms typically only attain the first position in one out of seven networks. While our LS algorithm takes the lead in two out of seven networks and secures second place in an additional two. We note that the best performing algorithms are well distributed among the benchmarks, which reflects that real networks have generally different generating mechanisms that are better captured by some algorithm than others26,27. This suggests that achieving optimal performance across all scenarios is highly improbable57, aligning with the No Free Lunch theorem27. It is, however, interesting that LS consistently ranks first or second in the four out of seven benchmark networks, and is overall the best classifier, suggesting that the notions of local dominance, hierarchy and community centers are pervasive in real networks, whose degree distributions are generally heterogeneous. It is also instructive to understand why LS does not perform well on the Football network8,58,59. It is due to the fact that the Football network is fairly homogeneous, and we have already explained why the LS method does not perform well in this situation, see the subsection on multiscale community detection. There is also significant connectivity between the largest degree nodes in the ground-truth communities, thus some of them become direct followers to others and their communities are merged. If a portion of links between the largest degree nodes were removed, the partition given by the LS method would be much closer to the ground truth.
Targeted link removal and addition can significantly change the structure of a network and the outcome of community detection algorithms. The LS algorithm is not immune to that effect, as it relies on local leaders to separate communities, therefore, intentional targeted link addition between two community centers would make one of them a follower and lead to just a single community, which will dramatically reduce the performance of the classification. For example, if we connected the president and instructor in the Zachary Karate Club network, then the LS method only yields a single community (Supplementary Fig. 24), which is the case before the split60. This also lends us a way to identify critical links for merging or splitting communities61. The identification of local hierarchy is, on the other hand, more robust against links missing or adding at random, see Supplementary Figs. 22-23.
In addition, the number of communities detected by LS is also closer to the ground truth, see Table 2. For example, for the Zachary Karate Club network, Louvain detects four communities, while LS detects two, which is consistent with reality. As usually more potential centers can be detected in real networks, see Supplementary Fig. 6, and might correspond to meaningful multiscale structure. As for the Polblogs network, where LS finds three instead of two communities indicated by current labeling, and there is debate whether three groups should be considered as the ground truth (i.e., apart from liberal and conservative, there is a neutral community)62. This partially explains why the LS does not work that well on this example. This also reflects the importance and difficulty of obtaining ground-truth labels, if there are any27. Although the evaluation of the classification performance of an algorithm with a ground truth is standard practice63, establishing the ground truth for community assignment usually require detailed survey, which can be difficult for very large networks40,63, and is usually regarded as distinct from metadata available27,40. The choice(s) of the ground truth(s) is crucial and there might be alternative ground truth that emerge from unsupervised clustering analysis and are validated a posteriori. The notion of alignment between ground truth and structure is indeed crucial to obtain good clusters64. For example, in the well known Zachary Karate Club network60, the metadata of nodes can also be their gender, age, major, ethnicity, however, most of which are irrelevant to the community structure when interested in understanding the split of the club27,40, but might be relevant to understand other type of community structure. Apart from evaluations based on ground-truth labels, various evaluation criteria purely based on network structure (e.g., optimizing modularity, conductance, cut) have been proposed, however, they may deviate from the real generating process of networks and will not be suitable for all scenarios. For example, maximizing modularity cannot generate good partitions in ecological networks, as herbivores in the same community will not prey on each other, thus there are no dense connections within the same ecological community. In this sense, if there can be some ground-truth labels, using F1-score is a more objective evaluation.
Applications to urban systems
Our final example of real-world networks is to uncover the structure of spatial interactions in cities. It also showcases the capacity of LS to adapt to weighted networks, with node degree replaced by the node strength and the least weighted shortest path, where the distance between two adjacent nodes is the reverse of the volume of mobility flow. Many cities have or will evolve from a monocentric to a polycentric structure65, which can be inferred from the patterns induced in human mobility data. We use human mobility flow networks derived from massive cellphone data at the cellphone tower resolution with careful noise filtering and stay location detection66,67,68 for three cities in different continents: Dakar69, Abidjan7,70, and Beijing71,72 (see references therein and Supplementary Material of Liu et al.’s work7 for more details on obtaining the mobility flow network from cellphone data). The LS algorithm can detect both communities with strong internal interactions and meaningful community centers, see Supplementary Fig. 8 for the decision graph. We find that for the smaller cities Dakar and Abidjan, communities are more spatially compact, while in the larger city, Beijing, they are more spatially mixed, see Fig. 4. This indicates that in Beijing, interactions are less constrained by geometric distance, which might be due to a more advanced transportation infrastructure and a superlinearly stronger and diversified interactions tendency in larger cities7,73,74. In addition, the identified community centers correspond to important interaction spaces in cities, see Fig. 4. For example, in Beijing, the top three centers are The China World Trade Center in Chaoyang District, the Zhongguancun Plaza Shopping Mall in Haidian District, and Beijing Economic and Technological Development Zone in Daxing District. In Abidjan, LS detects the Digital Zone, local mosques, and markets as centers. In Dakar, a university and some mosques are detected.


a Dakar in Senegal, Africa. b Abidjan in Côte d’Ivoire, Africa. c Beijing in China, Asia. Each dot represents a location, which corresponds to a region by Voronoi tessellation according to cellphone towers. Communities are indicated by different colors, and their centers are marked as stars. The decision graphs are shown in Supplementary Fig. 8.
Clustering vector data via the LS algorithm
Community detection and vector data clustering share many similarities, but are often considered separately and having contrasting focus. Our use of local leaders identified by local dominance was directly inspired by the concept of the center of a cluster, which is characterised by a higher centrality measure in its vicinity/neighborhood (e.g., density or degree) and a relatively long distance (i.e., a large li) to the nearest object with a large centrality. Local dominance concretely and explicitly identifies fundamental asymmetric leader-follower relation between objects, which naturally give rises to centers. This creates a direct link between the two viewpoints of network science and data science. It is therefore natural to ask whether LS would perform well, or even better, than vector data clustering methods on a discretised version of a data cloud.
To cluster vector data with the LS method, we first need to discretise it into a network. Many methods exist to perform this task, including ϵ-ball, k-nearest-neighbors (kNN) and its variants (such as mutual kNN, continuous kNN), relaxed maximum spanning tree75, percolation or threshold related methods35,76, and more sophisticated ones77. Here, we employ the commonly used ϵ-ball method that sets a distance threshold ϵ and connects vectors, which become nodes, whose ϵ-balls overlap, see Fig. 5a and inset. This process can be accelerated by using R-trees and are implemented in a time complexity of O(\(N\log N\))74,78 (see Supplementary Note 1.4). After traversing all nodes, a network encoding a geometric closeness within ϵ between nodes is obtained, see Fig. 5b. The ϵ-ball method preserves spatially local information, e.g., the vector density in the metric space can be interpreted as degree in the constructed network, and coarse-grains continuous distance between objects into discrete values. This makes the determination of centers clearer (see Fig. 5c, d). The choice of ϵ influences greatly the structure of the network obtained, here we chose ϵ to be near the network percolation value to ensure a minimally connected graph79,80,81, more details on determining ϵ can be found in Supplementary Note 3.1.


a An example of data cloud and b its dicretised network representation by (Inset) the ϵ-ball method. c The decision graph by the density and distance based (DDB) algorithm16. d The decision graph by the local search (LS) method. Cluster centers are data points of both a higher density ρi than its neighbors and relatively far from other points with a larger density (i.e., a large di)16. The density ρi of a data point i is simply the number of nodes within a certain radius ϵ, and it is equivalent to the degree of node i in the corresponding network (i.e., ki = ρi). The network constructing process is a coarse-graining and discretization process, where the absolute distance value is not preserved (e.g., in the Inset, d32 > d34 for the original vector data, but l32 = l34 = 1 in the network). The Euclidean distance between any data points is based on a global metric, but the topological path length between two nodes are based on a local metric. For example, d24 is only slightly larger than d34, but in the network, l24 = 2 and l23 = 1 (see the Inset); though d21 ≈ 2d23 according to global metric, node 2 and node 1 are not reachable in the network based on the local metric. Cluster centers identified by the DDB algorithm matches community centers identified by the LS method, which are all marked as stars.
Applying the LS algorithm on the constructed network for a series of well-known two dimensional benchmark data (Fig. 6a, e and Supplementary Fig. 10 for more cases), yields the expected clusters (Fig. 6b, f and Supplementary Fig. 11). By contrast, the Louvain algorithm generally obtains more and smaller clusters in a relatively fragmented way (Fig. 6c, g and Supplementary Fig. 13 for more examples) on the same networks. The reason is that the Louvain algorithm overlook the transitivity of local relations82. The state-of-the-art unsupervised clustering algorithm density and distance based (DDB)16 applied to the original vector data yields expected clusters in most cases, see Fig. 6d and the original work that introduces DDB16 for other examples. This confirms the universality of local hierarchy between objects and the analogy between our community centers and cluster centers. However, the DDB algorithm fails in the test case83 in Fig. 6h due to a mixture of local and global metrics in this associate rule83, which do not affect the LS method (see Fig. 6f). From a network perspective, certain dynamics can give rise to meaningful clusters with arbitrary shapes in metric space (e.g., synchronization or spreading dynamics are usually only possible along the manifold via local interactions but not through global ones). For example, different clusters in Fig. 6e or Supplementary Fig. 11c, g, h might correspond to groups of fireflies that are only able to synchronize within the group rather than between groups, as their interaction range is usually limited. In the situations above, the distance measured by the local metric is more appropriate than the one measured by the global metric, see a more in depth discussion in Supplementary Note 3.2. The good performance of the LS algorithm on vector data resides in the correct identification of the local dominance, i.e., finding the centers, from the local metric.

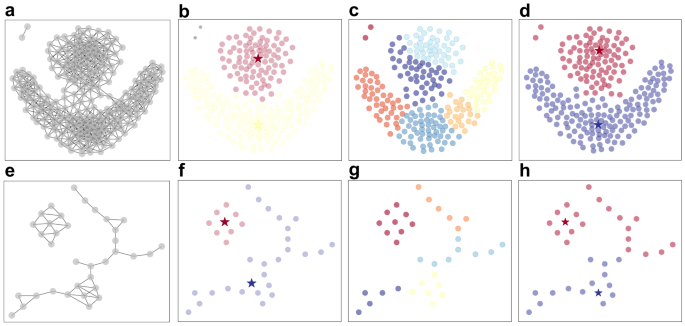
a represent the network constructed from vector data using the ϵ-ball method (see Supplementary Note 3.1 and Supplementary Fig. 10 for details on the network constructions). b shows the result of the LS method that correctly identify clusters that align with common consensus (see Supplementary Fig. 11 for more cases). In addition, LS can detect noisy points (marked in gray) that are of low degrees but long li. c shows the partitions obtained from the Louvain method, which are more fragmented than the LS result (see Supplementary Fig. 13 for more cases). d shows the result obtained from the DDB method which provides correct partitions to most benchmark data, see the original work that introduces DDB16 for other cases. e–h are the same as (a–d) for another vector dataset, where both a low density manifold and a high density cluster exist. In (h), DDB algorithm fails detecting correct clusters due to its local association rule83 being affected by a mixture of local and global metrics. LS and Louvain methods are performed on the constructed networks shown in (a) and (e), and the DDB algorithm is performed on the original vector data.
In addition, we show that the LS method is robust against noisy data in different scenarios, see Supplementary Note 4 and Supplementary Figs. 23-24. Though less common when considering vector data, targeted addition of edges in a network that connect two cluster centers, explicitly brings two cluster centers closer to each other in the metric space and will distort the space, whereas, conversely, the removal of links increases the distances between two objects.
The advantage of building networks for high dimensional vector data
We now show the advantage of combining the ϵ-ball discretisation and community detection methods on clustering high-dimensional data sets. Here, we use well-known benchmark datasets with very high dimensions: the MNIST (Modified National Institute of Standards and Technology) of hand written digits84, and Olivetti of human faces85, and show that our simple framework outperforms the-state-of-the-art DDB clustering algorithm16, see Table 4. Let us consider, for example, the Olivetti human face dataset, a challenging high dimensional dataset with small sample size. Each cluster obtained by the LS algorithm only contain images from a single individual, see Supplementary Figs. 17-19, simply based on Euclidean distance between images and without resorting to using complex image similarity measure. Moreover, it obtains a higher F1-score than the DDB method. We note that for MNIST and Olivetti datasets, the Louvain algorithm has a higher F1-score than LS, but identifies an inappropriately large number of clusters. The better performance of the Louvain algorithm lies in some subtle differences from clustering results obtained by the LS method (see comparisons between Supplementary Fig. 19a and Supplementary Fig. 19b for the Olivetti dataset with 100 images. The Louvain algorithm detects all images of the eighth person as one cluster, but the LS method classifies four images of the eighth person as another cluster).
We conjecture that the conversion from vector data to a network is not merely a translation of the data, but a fundamental information filtering process that accentuates the prominence of local leaders and thus increases the strength of local hierarchy, which in practice turns out to be a great advantage of our framework for handling vector data with high dimensions. Constructing the network via ϵ-balls is similar to a coarse-graining process: as long as two objects are close enough, the small differences in distances within ϵ are neglected. In addition, such a process also corresponds to subtracting irrelevant global information and puts the focus on similarity based on a local metric. Though there will be some information loss during the conversion from vector data to topological data, purely local information is enough to identify local dominance in the data. Not all information embedded in the vector data needs be utilized75, sometimes too much information might complicate the process. Although admitting asymmetric relations between objects would violate certain formal metric properties (e.g., distances are symmetric), it turns out to be an advantage for cluster analysis (see more discussions in Supplementary Note 3).
link